
Most teams integrating data science into application development believe they have crossed the finish line once a model is deployed, monitored, and returning predictions in production.
Pipelines are green, inference endpoints respond within SLA, and dashboards show stable metrics—yet business impact is flat, inconsistent, or quietly negative. This is not primarily a tooling failure, a data science failure, or even an engineering failure; it is a decision failure.
Integrating data science into applications fails not at deployment, but at the moment a prediction is converted into a product or business decision.
Until teams treat decision design and confidence handling as first‑class engineering problems, ML integration will continue to underperform—no matter how advanced the MLOps stack becomes.
Table of Contents
The Tooling Fallacy in Data Science Integration
Modern guidance around integrating data science and application development heavily emphasizes MLOps: CI/CD for models, feature stores, model registries, and automated retraining pipelines, often focusing on the underlying technology for AI and ML development.
These are necessary, but they are not sufficient. Industry retrospectives repeatedly show that a large portion of ML systems that reach production never meaningfully influence decisions or measurable KPIs.
In internal audits across fintech, e‑commerce, and SaaS platforms, a recurring pattern appears: models produce scores, applications consume them, but product logic neutralizes or bypasses them.
Common patterns include thresholds set conservatively and never revisited, fallback rules that dominate edge cases (which slowly become the majority of traffic), engineers adding hard overrides after one bad incident, and product teams changing flows without updating ML assumptions. The model technically exists and is “in production,” but it no longer drives outcomes.
As AI moves into more market‑sensitive and high‑risk applications, data scientists and app developers must work closely to design and ship AI features that are safe, observable, and aligned with product goals. When in‑house experience is limited, an external artificial intelligence service provider can help close architecture and integration gaps.
High‑level overviews of production ML failures echo this: most issues are about how models are used (or ignored) in decision flows, not about whether they can be deployed at all, as noted in analyses like Why Production Machine Learning Fails — And How To Fix It.
Prediction Is Not a Decision
A model output is not a decision; it is an input to a decision system. Yet most application architectures treat ML predictions as if they were deterministic answers rather than probabilistic signals.
A real decision requires confidence interpretation, risk tolerance, an explicit view of the cost of false positives vs false negatives, escalation paths, and failure handling.
Take a churn model that outputs 0.72. That number alone answers nothing. The real questions are: at what probability do we intervene, what intervention is triggered, what happens if the prediction is wrong, and who is accountable for the outcome?
When those questions are not answered explicitly, the application layer fills the gap with ad‑hoc logic—often scattered, undocumented, and silently diverging over time from the model’s original intent.
This gap—between prediction and decision—is where integration usually breaks. The model is “accurate enough” in offline evaluation, but the system that turns scores into actions is undefined, fragile, or owned by no one.
Decision Engineering: The Missing Discipline
High‑performing teams implicitly practice what can be called decision engineering, even if they do not use that label.
Decision engineering treats model‑driven decisions as engineered systems with explicit ownership, contracts, failure modes, and lifecycle management. This discipline sits between data science and application logic, and in most organizations it is left undefined.
As a result, data scientists optimize for metrics like accuracy and AUC, engineers optimize for reliability and latency, and product teams optimize for UX and conversion. No one owns decision quality end‑to‑end.
This misalignment explains why models are often blamed for failures they did not cause; the “last mile” between prediction and product behavior was never designed or maintained as a coherent system.
A parallel can be seen in broader data‑driven decision‑making literature, where the emphasis is on connecting analytics to decisions and accountability, not just building models, as outlined in guides like From Data to Decisions: Building a Data‑Driven Organization.
Decision Ownership Is the Real Bottleneck
In mature application development, APIs have owners, services have owners, and infrastructure has owners. But ML‑driven decisions often do not.
In production systems, repeated patterns emerge: engineers implement “temporary” safety rules that persist indefinitely, product teams override model behavior without informing ML teams, and models remain deployed but functionally irrelevant to business outcomes.
Once a decision has no owner, it decays. Decision decay is often more dangerous than model drift because it is invisible: the model still responds, dashboards still show predictions being generated, but the application no longer trusts or acts on them.
Without a clear owner accountable for the business behavior of a model‑driven decision, thresholds stagnate, fallbacks expand, and overrides accumulate until the ML component is effectively a no‑op.
Decision Contracts: Treat Decisions Like APIs
To integrate data science into applications sustainably, teams need decision contracts, not just data contracts. A decision contract defines:
-
Input assumptions: data freshness, schema guarantees, missing‑value behavior, and acceptable ranges.
-
Output semantics: what a score or label means operationally (e.g., “trigger outreach within 24 hours”), not just mathematically.
-
Acceptable error modes: which failures are tolerable and which are not, including trade‑offs between false positives and false negatives.
-
Fallback behavior: what the application does when confidence is low, inference fails, or upstream data is missing.
-
Kill‑switch criteria: when the decision system should be disabled or shifted to a safe default mode.
Teams that formalize decision contracts tend to see fewer production rollbacks, faster incident resolution, and higher long‑term ML adoption because the behavior of the decision system is explicit and versioned alongside the model.
This is rarely discussed in mainstream integration guides—despite its outsized impact.
The concept of formal contracts around ML behavior complements broader work on data and ML contracts described in resources like Why Data Contracts Matter More Than Model Accuracy.
The Core Conflict: Deterministic Apps vs Probabilistic Models
Traditional application development operates on a contract of certainty. When a user clicks “Save,” the data is saved; when they sort by price, the cheapest item appears at the top. The UI makes promises that the backend keeps. Users build a mental model of deterministic cause and effect.
Data science breaks this mental contract. A recommendation engine, churn predictor, or fraud detector is never “true”; it is “probable.”
If the UI treats a 55% prediction the same way it treats a 99% prediction, it effectively presents probabilistic guesses with the same confidence as guaranteed outcomes. When the model inevitably fails on low‑confidence predictions, users do not see a “statistical outlier”; they see broken software.
This is the hidden “Uncanny Valley” of logic: software that behaves with the confidence of hard‑coded rules but without the underlying certainty.
Successfully integrating data science and application development requires moving beyond merely connecting APIs to explicitly translating model confidence into appropriate UX and decision behavior.
Designing a Probabilistic UI: Confidence Tiers
The bridge between probabilistic models and deterministic user expectations is a probabilistic UI: interfaces and behaviors that change based on model confidence, similar to how modern products think about AI features in web and app development. Instead of treating all predictions equally, the application defines confidence tiers and maps each tier to different UI and decision behaviors.

Tier 1: High Confidence (e.g., >90%) → Automation
When the model is nearly certain and the cost of a false positive is acceptable for automation, the integration should be as invisible as possible.
The application acts on behalf of the user. The UI pattern is minimal friction: actions happen automatically based on model output.
An everyday example is spam filtering in email systems: high‑confidence spam is automatically moved out of the inbox, with an option for the user to correct mistakes.
This approach mirrors how many production systems use confidence thresholds for straight‑through automation, as seen in services like Azure Document Intelligence’s guidance on confidence thresholds.
Because false positives in full automation can be costly, this tier is reserved for actions where models demonstrate extremely high precision and where rollback mechanisms exist (e.g., a spam folder instead of silent deletion).
Tier 2: Medium Confidence (e.g., 60–90%) → Augmentation
The medium‑confidence zone is the “co‑pilot” tier. The model has a strong guess but requires human verification.
The UI language must shift from declarative (“This is the answer”) to interrogative (“Is this the answer?”). The user remains the editor; the model is an assistant.
Common UI patterns include suggestions, ghost text, “recommended” badges, or inline completions that require an explicit action—such as clicking a suggestion or pressing a key—to accept the AI’s input.
Systems like code completion tools and search autocomplete use this pattern extensively: if the model is wrong, the user simply ignores the suggestion, turning a potential failure into minor visual noise instead of a functional error.
Tier 3: Low Confidence (e.g., <60%) → Fallback
The most undervalued skill in integrating data science and application development is knowing when to show nothing.
When the confidence score drops below a defined threshold, the application should revert to deterministic logic or a generic, non‑personalized experience.
The UI pattern is the standard, non‑AI interface: normal rankings, default messaging, or unpersonalized recommendations.
Showing a clearly bad prediction is often worse than showing no prediction at all, because it directly undermines user trust.
A user will tolerate a generic list; they will not quickly forgive a personalized recommendation that feels nonsensical or intrusive.
The exact numeric boundaries for these tiers should always be domain‑ and risk‑specific, but the principle remains: confidence must drive both UI behavior and decision behavior.
Architecture: Where the Model and Decision Layer Sit in Your App
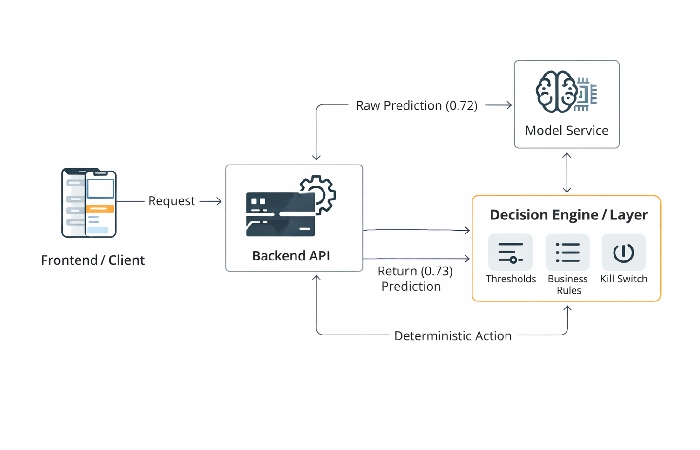
A clear architecture helps teams see where model outputs end and decisions begin. At a minimum, the flow looks like this:
-
Frontend: A user interaction or scheduled process triggers a request.
-
Application API: The backend receives context (user ID, event, features) and orchestrates downstream calls.
-
Model Service: The app calls a separate ML inference service (or library) that returns predictions, scores, and metadata.
-
Decision Layer: A distinct module interprets model outputs according to the decision contract: thresholds, confidence tiers, business rules, and fallbacks.
-
App Behavior and UI: The result of the decision layer drives what the user sees and what actions the system takes.
Crucially, the decision layer is not the model itself. It is the glue between probabilistic predictions and deterministic application behavior.
It can be implemented as a standalone service, a library, or a clear module in the application code, but it must be explicit, versioned, and owned.
Engineering the Confidence Contract: From JSON to UI
To implement a probabilistic UI and robust decision contracts, the standard API handoff must evolve. A simple JSON response containing only a label or ID is no longer sufficient for real‑world, evolving systems.
Anti‑pattern (old way):
——-
{
"recommended_product_id": "10452"
}
This response gives the frontend almost no information about how much to trust the recommendation, how to display it, or how to log decisions.
Probabilistic contract (improved way):
{
"prediction_id": "550e8400-e29b-41d4-a716-446655440000",
"prediction": {
"label": "10452",
"confidence_score": 0.78,
"model_version": "v4.2.1"
},
"alternatives": [
{ "label": "33211", "score": 0.12 }
],
"meta": {
"threshold_suggest": 0.60,
"threshold_auto": 0.92
}
}
In this contract:
-
prediction_id is a unique identifier that ties this prediction to logs and downstream analytics.
-
confidence_score allows the frontend and decision layer to place the prediction into the correct confidence tier.
-
model_version supports debugging and A/B testing across versions.
-
alternatives enable richer UI or fallback behavior.
-
meta encodes decision thresholds so the frontend and decision layer act consistently with the model’s intended use.
The frontend (or decision layer) then implements logic such as:
-
If confidence_score ≥ threshold_auto → automatically apply the action (Tier 1).
-
Else if confidence_score ≥ threshold_suggest → show as a suggestion requiring confirmation (Tier 2).
-
Else → ignore the prediction and fall back to deterministic behavior (Tier 3).
The frontend is no longer “just rendering data”; it is rendering trust and decisions.
Example: Turning a Churn Score Into Real Decisions
Consider a churn prediction model that, given a customer, returns a probability of churn in the next 30 days. Using decision contracts and confidence tiers, you can define concrete behaviors:
Score bands and actions (illustrative):
-
0.00–0.39
-
Action: No special treatment; rely on standard lifecycle messaging.
-
Owner: Lifecycle marketing.
-
Fallback: If model is unavailable, follow the same baseline journey.
-
-
0.40–0.69
-
Action: Show non‑discount retention prompts in‑app (e.g., check‑in message, feature tips).
-
Owner: Product + marketing jointly.
-
Fallback: Use rules based on inactivity (e.g., no login for 14 days).
-
-
0.70–0.89
-
Action: Trigger targeted outreach (personal email, support check‑in) and in‑app nudges.
-
Owner: Customer success.
-
Fallback: Prioritize by last seen + plan value if scores are unavailable.
-
-
0.90–1.00
-
Action: Offer limited retention incentives (discount, extended trial) with clear budget caps.
-
Owner: Revenue / growth.
-
Fallback: Manual review of high‑value accounts flagged by rules.
-
The model service could return a payload like:
——-
json
{
"prediction_id": "churn-1234",
"prediction": {
"score": 0.82,
"model_version": "churn_v3.1"
},
"meta": {
"tier": "HIGH",
"tier_definition": {
"low": [0.0, 0.39],
"medium": [0.4, 0.69],
"high": [0.7, 1.0]
}
}
}
The decision layer interprets this as “HIGH churn risk” and triggers the pre‑agreed action: targeted outreach plus in‑app messaging, logs the decision with prediction_id, and emits events so downstream analytics can measure intervention success and override rates.
Implementation Checklist for Decision Contracts
Before integrating a model into an application, teams can use a checklist to define the decision contract clearly:
-
Decision definition
-
What decision is being made (e.g., “offer retention incentive to this user today”)?
-
Is this decision reversible or irreversible?
-
-
Inputs and assumptions
-
What features are required, and what happens if any are missing?
-
What is the maximum acceptable data staleness (e.g., “features no older than 24 hours”)?
-
-
Thresholds and confidence handling
-
What score bands map to automation, augmentation, and fallback?
-
How often will thresholds be reviewed and by whom?
-
-
Overrides and kill switch
-
Under what conditions may humans override model decisions, and how are overrides logged?
-
When must the model be disabled (e.g., abnormal drift, spike in complaints, regulatory changes)?
-
-
Fallback behavior
-
What deterministic rules or default flows run when the model is unavailable or below a minimum confidence?
-
-
Metrics and monitoring
-
Which KPIs indicate the decision is working (e.g., churn reduction, fraud caught, support tickets avoided)?
-
Which metrics track decision quality (override frequency, intervention success, error reports)?
-
This checklist keeps the focus on decision outcomes, not just prediction quality, and makes maintenance responsibilities explicit from day one.
The “Cold Start”: Faking Confidence Until You Train It
A common roadblock in integration is the “zero data” problem: how to build a decision‑aware interface when there is not yet a trained model.
The secret is that you do not need a fully trained model to begin designing and testing the decision layer and probabilistic UI.
On day one, teams can use simple heuristics (if/then rules) to simulate confidence and drive the same architecture that a future model will use.
For example, if a user has visited the pricing page three times in a week, you might assign a “high” pseudo‑confidence score to the “Contact sales” recommendation.
The UI and decision layer respond to these synthetic confidence scores the same way they will later respond to model‑generated scores.
This approach lets you ship the probabilistic UI immediately. Even though the “brain” is simple, the “body” (the interface) starts collecting user interaction data—accepts, rejects, ignores—that will be invaluable for training and evaluating a real ML model later.
Architecting the Feedback Loop: The “Oops Loop”
The true power of a Tier 2 (augmentation) interface is that it captures implicit human feedback. Most teams log predictions in one system (ML logs) and user actions in another (app logs), with no reliable way to join them. This prevents the model from learning from its mistakes and from real‑world edge cases.
To fix this, you need a closed‑loop architecture:
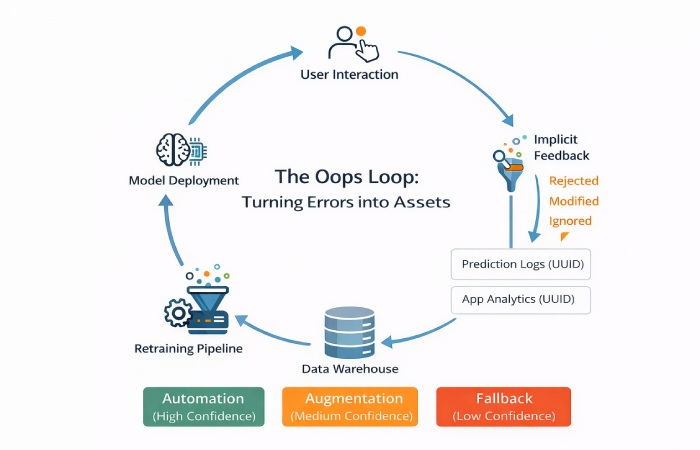
1. Traceability
Every prediction generated by the backend must have a unique prediction_id (for example, a UUID).
The frontend must attach this ID to any subsequent analytics events related to that UI element or decision.
This enables offline analysis of how users actually responded to specific model outputs.
2. Feedback taxonomy
Standardize how the frontend reports success or failure via behavior, not just explicit thumbs‑up/thumbs‑down buttons. An event schema might look like:
———-
json
{
"event_type": "prediction_interaction",
"prediction_id": "550e8400-e29b-41d4-a716-446655440000",
"outcome": "MODIFIED", // ACCEPTED, REJECTED, IGNORED, MODIFIED
"interaction_time_ms": 450,
"value_modified_to": "Correct value"
}
-
-
ACCEPTED: The user took the action or left the suggestion as‑is.
-
REJECTED: The user explicitly canceled, dismissed, or undid the suggestion.
-
MODIFIED: The user accepted but edited the AI output (extremely valuable for training).
-
IGNORED: The user scrolled past or continued without engaging.
-
3. Data flywheel
These events should not just sit in dashboards. They form the test set and training data for the next model iteration—particularly the MODIFIED and REJECTED cases that reveal where the model is wrong or incomplete.
This style of joined telemetry echoes broader recommendations from model monitoring and observability practices that stress linking model inputs, outputs, and user outcomes for continuous improvement.
Any change to model code or decision logic should trigger automated tests and controlled deployment through your CI/CD pipeline. In cloud setups, teams often pair services like Azure Machine Learning with Azure DevOps so retraining and rollout are repeatable and auditable, while data‑lake triggers can launch retraining jobs and a nocode development app lets non‑engineers safely adjust workflows without editing core model code.
Model Drift vs Decision Decay: Observability Beyond Accuracy
Once the feedback loop is in place, a new risk emerges: model drift and decision decay. Model drift occurs when the input data distribution or relationships change over time, causing prediction quality to degrade.
Decision decay happens when thresholds, rules, or business context change without corresponding updates to the decision layer.
Monitoring only infrastructure metrics (uptime, latency) is not enough. The engineering team needs an alert system for confidence distributions and tier frequencies as well:
-
If the percentage of Tier 1 (automation) predictions suddenly drops or spikes, the automation experience may be silently breaking.
-
If override rates or complaint rates suddenly spike, decision quality may be degrading even if accuracy metrics appear stable.
Setting alerts on such metrics and regularly reviewing decision metrics aligns with model monitoring best practices advocated by many ML observability tools, which emphasize watching both model health and downstream business impact.
How to Test the Unpredictable: Mock Confidence, Not Just Data
A common objection to probabilistic, decision‑aware architectures is QA: how to write integration tests when backend outputs change based on probability and model evolution.
The key is to separate testing the model from testing the application’s reaction to model outputs.
In your test suite (Cypress, Selenium, Jest, etc.):
-
Do not call the live ML endpoint.
-
Mock the model response to force specific confidence tiers and decision paths.
Example test cases:
-
Case A: confidence_score = 0.95
-
Assert that the UI performs the action automatically (Tier 1/automation behavior).
-
-
Case B: confidence_score = 0.70
-
Assert that a suggestion or “Did you mean?” banner appears and requires user confirmation (Tier 2/augmentation).
-
-
Case C: confidence_score = 0.40
-
Assert that the standard deterministic UI loads with no AI‑driven changes (Tier 3/fallback).
-
Because probabilistic UIs are dynamic, use visual regression or snapshot testing to ensure that when suggestion banners or inline completions appear, they do not break layout or core workflows.
Model accuracy can be validated separately in offline tests and shadow deployments, while UI integration tests focus on how the application responds to different confidence patterns.
Why Notebook‑First ML Makes Decision Failures Worse
Notebook‑driven workflows optimize for experimentation speed on static datasets, not for designing long‑lived decision systems.
They encourage offline assumptions, perfect labels, and zero latency constraints, and they often hide or hard‑code decision logic (thresholds, costs, trade‑offs) inside exploratory code or metrics notebooks.
By the time engineers ask, “What should the app do with this prediction?”, the model is often already locked into a particular shape and set of assumptions.
Decision logic tuned implicitly on historical data may never be revisited once embedded into production code.
This is one reason many production ML systems are rewritten rather than refactored: the decision layer was never cleanly separated from experimentation code. Decision design must precede model training—not follow deployment.
Why Accuracy Metrics Collapse in Production
Many integration guides still emphasize monitoring accuracy, precision, and recall in production. In practice, those metrics can be difficult or misleading in live systems:
-
Ground truth may be delayed or unavailable (e.g., churn that manifests months later).
-
Labels may be biased by previous decisions (e.g., only investigated cases get labeled), creating feedback loops.
-
Changes in user behavior, product design, or population mix can distort metrics that were calibrated offline.
Experienced teams track decision impact in addition to prediction quality.
Examples include intervention success rates (did the chosen action help?), override frequency (how often humans or rules disagree with the model), business deltas versus control paths (did the decision path beat a non‑ML baseline?), and cost per prevented error or saved unit of risk.
If you cannot measure the outcome of a decision, you are not truly integrating data science—you are guessing with confidence.
This perspective aligns with broader guidance that stresses linking models to business KPIs rather than optimizing accuracy in isolation.
The Long‑Term Cost: Decision Debt in Year Two
Most ML systems do not fail at launch; they fail quietly 12–24 months later. Symptoms of decision debt include:
-
Thresholds never revisited despite changes in user base, product, or market.
-
Features that change meaning (e.g., repurposed fields, new product lines) without updating the model or decision logic.
-
Business context shifting so that the original objective is no longer relevant.
Over time, rules begin to replace models, retraining stops, and the model remains in architecture diagrams only.
The system “works” in the narrow sense of returning scores, but those scores no longer matter to real decisions. This is decision debt—not just technical debt—and it is a primary reason ML initiatives stall after an initial burst of success.
Steps to Integrate Data Science Into Your Application Safely
Bringing these concepts together, experienced teams walk through a consistent sequence before and during integration:
-
Define the decision, not just the model
-
What decision will the model influence?
-
How can that decision fail safely, and what are acceptable trade‑offs?
-
-
Assign decision ownership
-
Name a clear owner (often a product or business owner) accountable for decision outcomes, with engineering and data science as co‑owners of execution and model behavior.
-
-
Design the decision contract and confidence tiers
-
Specify inputs, outputs, thresholds, fallbacks, overrides, kill switches, and UI behaviors per confidence tier.
-
-
Implement architecture with a distinct decision layer
-
Place the decision layer between the model service and the rest of the app, and ensure it is versioned, logged, and observable.
-
-
Wire a probabilistic UI where appropriate
-
Use automation for high‑confidence, low‑risk cases, augmentation for medium‑confidence suggestions, and fallbacks when confidence is low.
-
-
Instrument feedback and monitoring
-
Log prediction_id, confidence, decision taken, and user behavior, and monitor both model health and decision impact metrics.
-
-
Review and evolve decisions, not just models
-
Regularly revisit thresholds, contracts, and ownership as business context and data evolve.
-
Conclusion: The Competitive Advantage Nobody Markets
MLOps is necessary. Infrastructure matters. Tooling helps. But the real differentiator in integrating data science and application development is decision ownership and the translation of probabilistic outputs into trustworthy, observable decisions and interfaces.
Teams that succeed are not just better at deploying models; they are better at designing, owning, monitoring, and retiring decisions. They treat prediction as an input, confidence as a first‑class signal, and the decision layer as a core part of their application architecture. That is the part few vendor blogs emphasize—and it is precisely where integrated data science can move from quiet failure to durable advantage.
Frequently Asked Questions (FAQ)
What does integrating data science and application development actually mean?
It means embedding data‑driven decision logic into live applications—not just deploying models, but ensuring predictions reliably influence product behavior and business outcomes, with explicit contracts, ownership, and feedback loops.
Why do many production ML models fail to deliver business impact?
Because the decision layer is undefined. Models generate predictions, but thresholds, fallbacks, and ownership of outcomes are unclear, so models are bypassed, neutralized, or quietly replaced by rules and overrides.
Is MLOps enough to integrate data science into applications?
No. MLOps covers deployment, scaling, and monitoring of models, but it does not define who owns model‑driven decisions, how failures are handled, or how predictions map to real actions in the application.
What is decision engineering in ML systems?
Decision engineering is the practice of explicitly designing, owning, and governing how model outputs become business actions, including thresholds, confidence handling, overrides, kill switches, and metrics.
Who should own model‑driven decisions in an application?
Ownership should be explicit and cross‑functional: product defines intent and success, engineering owns execution and reliability, and data science owns model behavior. One accountable owner must ultimately be responsible for outcomes.
Should ML predictions always be used in real time?
No. Many applications perform better with batch scoring, cached predictions, or hybrid rule‑plus‑ML systems that reduce latency, cost, and operational risk while still leveraging model insights.
How do teams measure ML success when accuracy can’t be tracked easily?
By monitoring decision impact metrics such as intervention success rate, override frequency, user complaints, and business KPIs (revenue, churn, risk) rather than relying solely on raw accuracy or AUC.
Why do ML systems often get removed after a year or two?
Because decision debt accumulates. Thresholds stagnate, data semantics shift, business context changes, and no one maintains the decision logic tied to the model, so the safest path becomes turning the model off.
What is a decision contract in ML integration?
A decision contract documents how predictions are used, including input assumptions, output semantics, acceptable errors, fallback behavior, override rules, and conditions for disabling the model.
What should be defined before training a production ML model?
The decision the model will influence, acceptable failure modes, ownership, confidence and threshold strategies, and how success will be measured. Model training comes second; integration and decision design come first.
Disclosure
This content has been prepared based on industry case studies, engineering postmortems, and real-world production practices across data science and application development teams. AI assistance was used to structure, refine, and clearly communicate complex operational insights for experienced technical readers.